
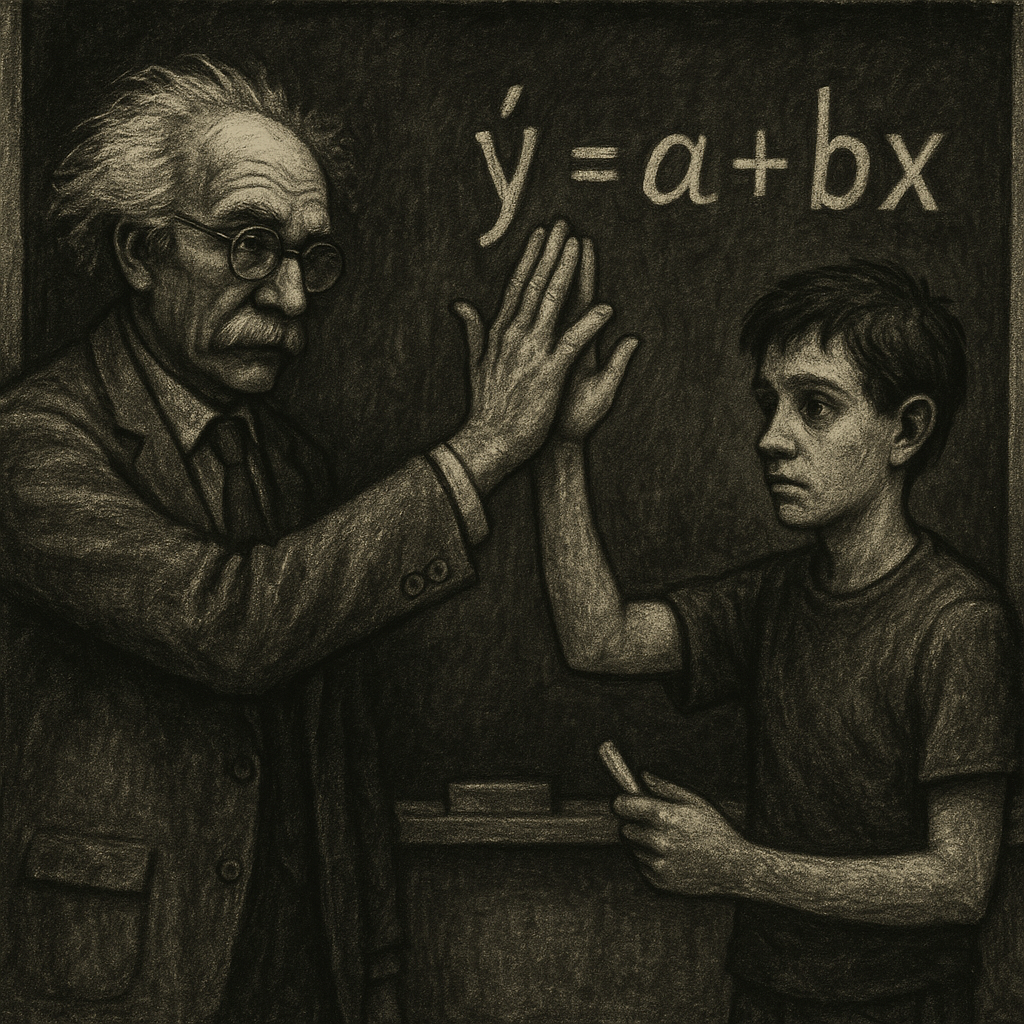
Resources
The Breakdown
Important
- Null Hypothesis (H0) – The idea that there is no relationship or difference between variables or groups. In inferential statistics, the primary objective is to test this hypothesis.
- P-value – A crucial criterion used to determine whether statistical results are significant. If the observed p-value is equal to or lower than 0.05, the results are considered statistically significant, leading to the rejection of the null hypothesis.
- Confidence Interval (CI) – A range of values, specified by a lower and upper bound, derived from estimates, which indicates where a population parameter is expected to fall. A 95% CI is commonly used when the significance level is set at 0.05. If a confidence interval does not contain zero, the results are significant; if it does contain zero, the results are not significant.
- Type I Error – This occurs when a researcher mistakenly concludes that results are significant (i.e., rejects the null hypothesis) when, in reality, they are not.
- Type II Error – This occurs when a researcher mistakenly concludes that results are not significant (i.e., keeps the null hypothesis) when, in reality, they are significant, representing a missed opportunity to detect a true effect. Strategies to manage these errors include increasing sample size, decreasing the p-value (e.g., through p-value adjustment like Bonferroni correction), and reducing measurement error.
- Common Statistical Tests – It is important to understand when and why to use the most common statistical tests, including Z-test, Pearson correlation, T-tests (one-sample, paired sample, independent), Linear regression, ANOVAs, Logistic regression, Ordinal regression, and Chi-square.
- Z-test Conditions – For a Z-test to be appropriate, the population mean and variance/standard deviation must be known, the sample size should be 30 participants or more, and the sample distribution must be approximately normal.
- Cross-tabulation (Contingency Table) – This statistical tool is vital for displaying the relationship between two or more categorical variables in a table and is a necessary preliminary step before conducting a chi-square test. It organises data into rows, columns, and cells, displaying frequencies and totals.
Core concepts
- Descriptive vs. Inferential Statistics: Descriptive statistics are used to describe and summarise data, focusing on understanding its distribution without predicting or testing relationships or generalising to a population. In contrast, inferential statistics enable researchers to make inferences, predict outcomes, test relationships, and compare samples with populations, often involving hypothesis testing.
- Alternative Hypothesis (H1): Also known as the researcher’s hypothesis, this is the idea that a relationship or difference exists between variables or groups. If statistical results are significant and the null hypothesis is rejected, the alternative hypothesis is supported.
- Statistical Significance Criteria (Alpha): The significance level, denoted as alpha ($\alpha$), represents the probability of incorrectly rejecting the null hypothesis (a Type I error). The standard criterion for statistical significance is typically set at a p-value of less than 0.05.
- Directional (One-tailed) Hypothesis: This type of hypothesis is used when researchers specify the expected direction of associations or comparisons, for example, hypothesising a “positive relationship” between two variables. This is typically employed when there is prior evidence or a strong theoretical basis supporting a specific direction.
- Non-Directional (Two-tailed) Hypothesis: This hypothesis is used when researchers do not specify the direction of associations or comparisons, simply stating that a relationship or difference exists without predicting its nature (e.g., positive or negative). This is suitable when the expected direction is uncertain.
- One-sample t-test: An alternative to the Z-test, this test examines differences between a sample mean and zero or a specified mean when the population variance or mean is unknown. It is robust to violations of normality assumptions.
- Paired Sample (Dependent) t-test: This test is applied in repeated-measures or within-subject designs, allowing for the comparison of means within the same group of participants across two conditions, waves, or time points.
- Independent t-test: Used to compare means between two distinct and independent groups of participants (a between-subject design).
- ANOVA (Analysis of Variance): This statistical test is employed to compare the means of more than two groups when the outcome variable is continuous.
- One-way ANOVA: Compares means among three or more independent groups.
- Repeated Measure ANOVA: Used for within-subject designs with more than two time points, conditions, or waves, where the same participants are measured multiple times.
- Correlation: Used to test the relationship, association, or correlation between two or more variables.
- Pearson Correlation: Applied when both variables are continuous or quantitative.
- Spearman Coefficient: Used when at least one variable is ordinal.
- Direction and Strength: Correlation coefficients range from -1 to +1. Positive values (closer to +1) indicate that as one variable increases, the other also increases; negative values (closer to -1) indicate that as one variable increases, the other decreases; a value of 0 indicates no relationship. The strength is categorised: weak (less than 0.39), moderate (0.40–0.69), and strong (greater than 0.70).
- Interpretation: In inferential statistics, the significance (p-value) of a correlation should be assessed before discussing its direction and strength.
- Chi-square test: This test determines whether there is a significant association between two categorical variables (Test of Independence) or if observed frequencies in a dataset differ from expected frequencies (Goodness-of-Fit Test). It is used when both variables are categorical and nominal.
- Regression: A statistical technique used to examine the relationship between one or more independent variables (predictors) and a dependent variable (outcome), typically for prediction, understanding, or analysing how the dependent variable changes.
- Linear Regression: Used when the outcome variable is continuous.
- Ordinal Regression: Used when the outcome variable is ordinal.
- Logistic Regression: Used when the outcome variable is binary (e.g., yes/no).
- Simple Regression: Involves a single predictor variable.
- Multiple Regression: Involves two or more predictor variables.